 不久前,美国人形机器人公司 Figure 提出能让机器人「抓取万物」的 Helix 模型,一时间引发轰动。
不久前,美国人形机器人公司 Figure 提出能让机器人「抓取万物」的 Helix 模型,一时间引发轰动。
事实上,几乎同一时间,中国灵初智能团队提出了 DexGraspVLA 模型,该模型达到了在零样本真实环境中对上千种未见物体、光照和背景组合实现超过 90% 的抓取成功率,但训练数据仅为 Helix 的 0.4%。
这家成立不到半年的初创公司,近日连续刊发四篇高质量论文,将团队在取物能力泛化、利用外部环境配合抓取、堆叠场景高速检索以及 VLA 安全对齐等方向的成果公开。这意味着国内在具身智能领域的强大实力。
为什么机器人抓东西总像「手残党」?
在机器人领域,灵巧抓取是一个基础但极具挑战性的问题。
基础在于灵巧抓取能力是机器人通用性的一项重要指标,绕不开。而极具挑战性则在于,抓取能力能否泛化,要做到像人类一样能够在各种复杂场景中抓取不同物体,是业内头疼的问题。泛化能力受限,机器人便很难称得上「多面手」。
想象一下,让机器人抓取一个光滑的玻璃杯、松软的毛绒玩具,或者形状不规则的螺丝刀——这看似简单的任务,对机器人来说却堪比「地狱级挑战」。现有技术常面临三大难题:
场景单一:传统方法只能在固定光照、固定背景、固定物体下照本宣科,一旦遇到新环境就「傻眼」;
依赖人工预设:需要工程师提前标注物体形状、材质参数,就像让机器人「背答案考试」;
动作僵硬:机械手往往只能做「张」「握」等固定动作,难以像人类手指灵活调整力度和角度。
可以想象,当机器人抓鸡蛋时,可能因为预设力度过大直接捏碎,或者因光线变化误判鸡蛋位置,空手而归。
正因这种抓取能力因环境改变而出现的极大不稳定,研究团队试图研究一种能够将抓取能力泛化到不同场景的技术架构。
DexGraspVLA :以「域不变」应「场景万变」
这篇论文,提出了一种助力机器人多场景灵巧抓取物体的技术框架——DexGraspVLA。DexGraspVLA是一个用于灵巧手抓取的 VLA(Vision-Language-Action) 分层框架,它由一个基于视觉语言模型(VLM)的高层规划器和一个基于扩散模型的低层控制器组成,旨在通过少量训练,使灵巧手拥有在多变环境中的可靠抓取能力。其中:
高层规划器(High-level Planner):由预训练的大型视觉语言模型(VLM)实现,可理解多样化指令、自主决定抓取策略。
低层控制器(Low-level Controller):由扩散策略通过实时视觉反馈,闭环抓取目标物体。
整个框架的核心在于将多样化的图像输入数据通过现有的 Foundation Model 转换成域不变(Domain-invariance)的表征,并端到端地训练下层控制模型。
域不变性(Domain-Invariance)指模型在不同数据分布(即不同“域”)中仍能保持稳定性能的能力。
DexGraspVLA 能够将感知上多样的原始输入转换为域不变的表征,即使在视觉上差异巨大的环境中(如白色桌子、校准板、桌布和迪斯科灯光下的桌布),DINOv2 提取的特征、Cutie 跟踪的物体掩码以及 DiT 的注意力图都保持高度一致。
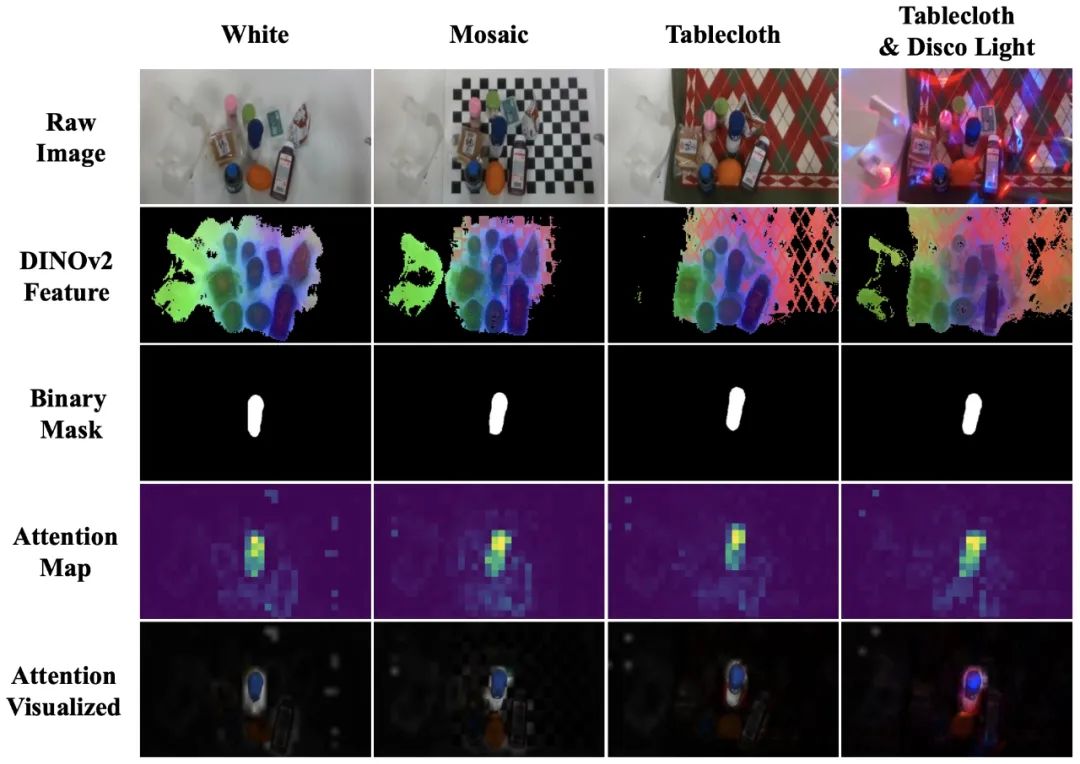 由于 DexGraspVLA 将原始输入转换为域不变表示,域偏移问题得到缓解,进而可以较好地应用模仿学习,对从表示到动作分布的映射进行建模,完成机器训练。
由于 DexGraspVLA 将原始输入转换为域不变表示,域偏移问题得到缓解,进而可以较好地应用模仿学习,对从表示到动作分布的映射进行建模,完成机器训练。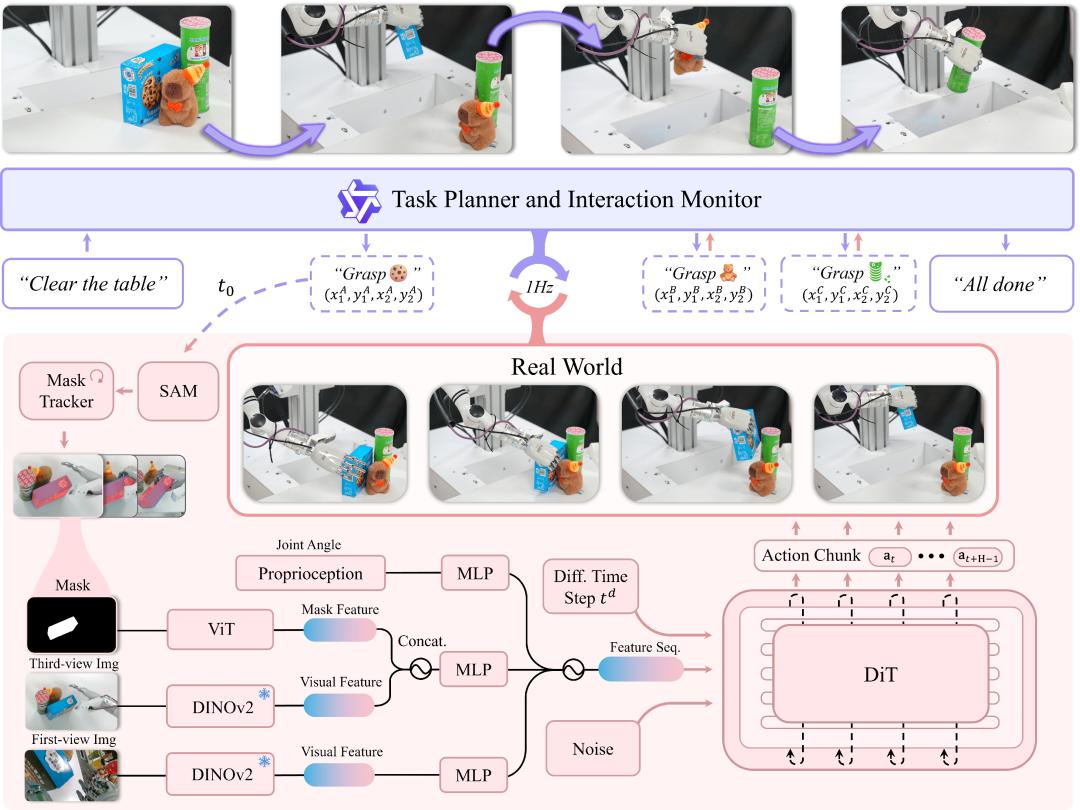 该框架具体工作流程如下:
该框架具体工作流程如下:
首先,高层规划器采用预训练的视觉语言模型 「Qwen2.5-VL」来对用户指令进行推理。例如,「清理桌子」。当指令涉及多个物体时,规划器会将其分解为单独的指令,如 「抓取饼干」,并通过在头部摄像头视图中提供一个边界框来定位目标物体。通过使用边界框,规划器确保了与控制器之间的域不变性(Domain-invariance)通信,无论语言或视觉输入如何变化。
而后,低层控制器接收边界框并执行实际的抓取操作。它首先利用两个分割模型,即通过 SAM(Segment Anything Model,分割一切模型)来获取目标物体的初始掩码,以及 Cutie 模型来持续跟踪掩码。接下来,两个固定的 DINOv2 特征提取器对来自头部和腕部摄像头的视觉信息进行编码,同时一个可训练的视觉 Transformer 处理跟踪到的物体掩码,以生成丰富的语义表示。这些表示在相对意义上是域不变的,从而促进了基于扩散模型的策略的学习过程。
紧接着,结合机器人的本体感受状态,这些信息通过多个多层感知器(MLP)模块投影到一个统一的特征空间中。然后通过一个扩散 Transformer 从这些组合特征中预测多步动作。与此同时,通过迭代去噪过程,它优化潜在动作标记以生成准确的运动规划。值得注意的是,在系统推断出一组新的动作之前,仅执行每个预测序列的第一个子集,以确保实时适应性。
在执行过程中,高层规划器以大约 1 赫兹的频率监控进展情况。如果抓取成功,它会触发一个预设的放置动作,将物体放入袋子中,并重置机器人。如果抓取失败,它会使用更新的信息重新初始化该过程。这个循环会一直持续,直到用户指令完成为止。
通过大型基础模型将各种输入转换为域不变的表征,DexGrasp VLA 成功地减轻了域迁移问题,并能够泛化到各种未见过的场景中。其高层推理与基于扩散模型的控制的协同作用,为长时程的灵巧抓取提供了一个强大且适应性强的解决方案。
机器人训练领域的 DeepSeek 时刻
从训练效率来看,该研究团队为了训练灵巧抓取策略,手动收集了 2,094 个在杂乱场景中抓取的成功片段(约 2 小时,2,094x3.5s)。数据集涉及 36 种家用物体,涵盖广泛的尺寸、重量、几何形状、纹理、材料和类别。每个片段记录了每个时间步的原始相机图像、机器人本体感知、物体掩码和动作。
 而此前人形机器人初创公司 Figure 在训练 Helix 这款 VLA 模型时,用到了 500 小时的高质量监督数据。这样比较,DexGraspVLA 的数据利用率是 Helix 的 250 倍。
而此前人形机器人初创公司 Figure 在训练 Helix 这款 VLA 模型时,用到了 500 小时的高质量监督数据。这样比较,DexGraspVLA 的数据利用率是 Helix 的 250 倍。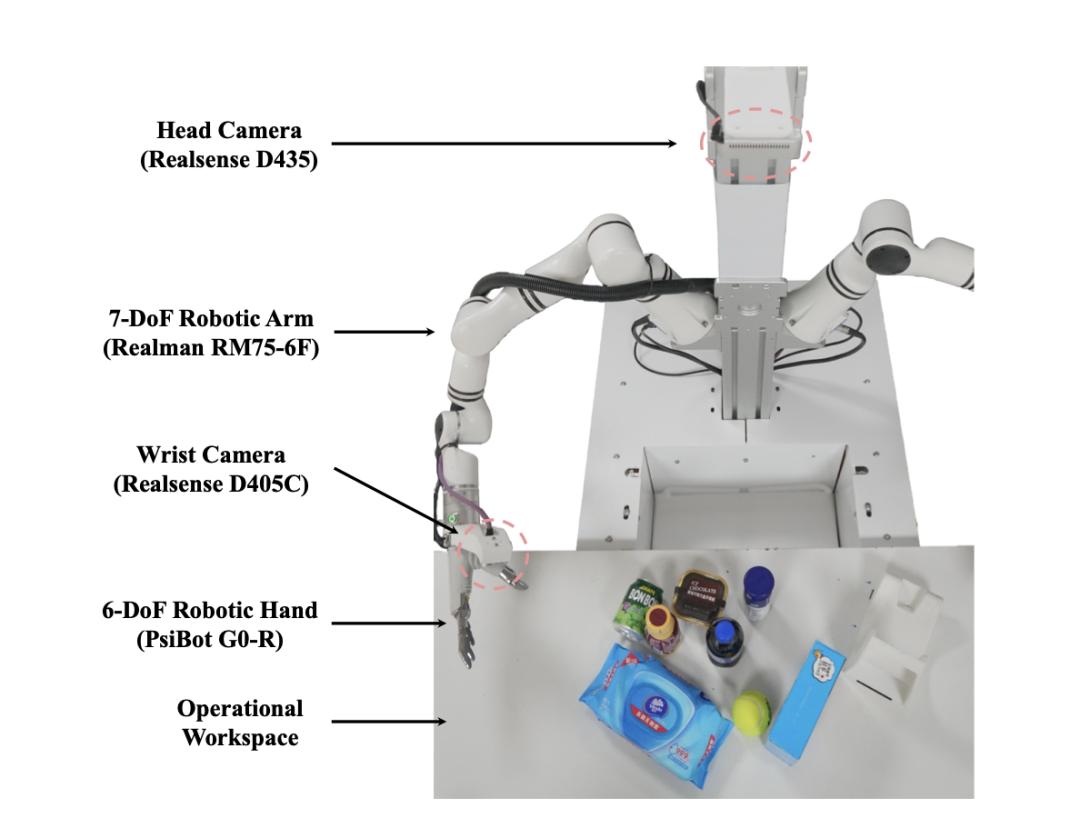 从训练成果成果来看,研究团队利用 360 个未见物体、6 个未见背景和 3 个未见光照条件等维度,组成 1,287 种未见的杂乱场景,将 DexGraspVLA 搭载于「7 自由度的 Realman RM75-6F 手臂 +6 自由度的 PsiBot G0-R 灵巧手」的硬件上, 在数千个场景中实现了 90.8% 的聚合成功率,展示了优秀的泛化能力。这种能力与号称「可拾取万物」的搭载 Helix 的 Figure 02 不分伯仲。须知,Figure 02 的手部拥有 16 自由度,灵活性远高于 DexGraspVLA 搭载的手部硬件。
从训练成果成果来看,研究团队利用 360 个未见物体、6 个未见背景和 3 个未见光照条件等维度,组成 1,287 种未见的杂乱场景,将 DexGraspVLA 搭载于「7 自由度的 Realman RM75-6F 手臂 +6 自由度的 PsiBot G0-R 灵巧手」的硬件上, 在数千个场景中实现了 90.8% 的聚合成功率,展示了优秀的泛化能力。这种能力与号称「可拾取万物」的搭载 Helix 的 Figure 02 不分伯仲。须知,Figure 02 的手部拥有 16 自由度,灵活性远高于 DexGraspVLA 搭载的手部硬件。
此外,DexGraspVLA 框架还实现了闭环姿态矫正与重抓取、长程抓取任务推理等突破。
总的来说,DexGraspVLA 框架得益于将多样的语言和视觉输入迭代转换为域不变表示,从而实现对广泛真实世界场景的鲁棒泛化。这意味着,DexGraspVLA 技术运用在机器人身上时,机器人的抓取能力将得到长足提升,进而提升机器人的通用能力。
写在最后
灵初智能等团队的 DexGraspVLA 与 Figure 公司的 Helix 几乎同一时间推出,而且方案逻辑极其相似。二者本质上都是双系统协同的端到端模型,DexGraspVLA 的低层控制器、高层规划器与 Helix 的 S1、S2 都分别起着「快慢脑」的作用,而快慢脑的组合,实现了机器人在多场景下的能力泛化。
这不仅仅是技术巧合,更多地反映了技术趋势。当前机器人的能力泛化正是靠端到端的技术方案拓展,一方面要依靠 VLM 这一慢脑对视觉与语言的理解,进而规划与推理,另一方面要依靠快脑对慢脑语义表征的进行实时转化,转化为精确的动作。(有关 Helix 的信息,参考《》)
值得注意的是,24 年 9 月成立于北京的灵初智能,11 月刚完成天使轮融资。作为成立不足半年的初创团队,近日其接连发四篇高质量论文,其他三篇的大致方向为:利用外部环境抓取单手抓不起的的物品;堆叠场景高速检索;安全对齐。而 DexGraspVLA 框架仅是其 Psi R0.5 端到端强化学习 VLA 模型的一部分。
作者:堃方
原标题:《狙击 Figure ,灵初智能团队研发分层 VLA 模型,数据利用率高 250 倍》
成为付费用户可以阅读 灵初智能 所有资料
了解更多 →