要想真正做到通用机器人,除了做好触觉AI,别无选择。
作者|苏霍伊
编辑|王博
今年以前,Sharpa都很神秘。
很多人以为Sharpa是一个做机器人灵巧手公司,因为Sharpa灵巧机械手Wave在ICRA 2025、CES 2026、GTC 2026连续亮相,还登上了今年总台央视春晚的舞台。它能精准发牌、打乒乓球、盘核桃,实现如同人手一般的精细化操作。

Sharpa灵巧机械手Wave在GTC上展示,图片来源:Sharpa
但Sharpa对自己定位远不止于此。
在GTC 2026上,Sharpa通过实物和视频展示了其完整技术栈,包括灵巧机械手Wave、人形机器人North以及融合视觉、触觉与语言的模型系统CraftNet。

Sharpa人形机器人North,图片来源:「甲子光年」拍摄
Sharpa成立于2024年,全球总部位于新加坡,制造与研发中心位于中国上海,商业运营总部位于美国加州硅谷山景城。虽然Sharpa创始团队因为过往在自动驾驶领域的经历而受到关注,但是Sharpa一直保持着独立运营的状态。
近期,「甲子光年」来到了Sharpa硅谷办公室,见到了Sharpa GTM副总裁、欧洲区总裁Alicia Veneziani和Sharpa研究科学家、学术负责人张凯峰。
这是Sharpa核心团队成员首次与媒体进行深度对话,对于外界好奇的公司定位,Alicia Veneziani告诉「甲子光年」:“我们的秘密武器是触觉AI,我们的核心定位是一家以触觉AI为驱动的全栈灵巧机器人公司。”
相比主要依赖视觉的机器人动作,Sharpa更专注于触觉驱动的机器人灵巧操作。
这一能力被认为是机器人完成复杂现实任务的关键门槛。宇树科技创始人、CEO王兴兴近期表示:“我觉得目前对于具身智能或者机器人来说,移动和动作大部分问题已经解决掉了,但对于抓取和操作这部分,尤其触觉相关的问题目前没有解决,这也直接限制了具身智能或者人形机器人大规模在工厂和家庭去部署。”
过去两年,具身智能行业的叙事几乎被视觉与语言主导:VLM、VLA、世界模型……让机器人看懂世界成为主线。但Sharpa选择了一条更难、也更少人走的路径:从“手”的感知出发,而不仅仅依赖“眼睛”。
Sharpa的技术路径建立在两个核心能力之上:一是通过仿真环境进行大规模技能训练;二是结合视频与触觉数据,训练其视觉-触觉-语言-动作模型(VTLA),使机器人能够学习人类的操作方式,并实现更高程度的自主化。
为支撑这一训练范式,Sharpa在GTC期间宣布与英伟达联合开发Tacmap仿真触觉系统,作为触觉驱动机器人学习的重要基础设施。该框架通过共享的高精度几何结构表示,实现了高真实度与高计算效率之间的平衡。Sharpa表示,相关仿真框架及代码资产未来将开源,以便与更广泛的机器人社区共享研究成果。
Alicia Veneziani和张凯峰,一位站在市场战略前线,一位深入模型系统底层。这次对话中,我们探讨了五个方面的话题:
Sharpa为什么会引发关注?
触觉是不是灵巧操作的关键?
CraftNet的创新之处?
为什么英伟达会和Sharpa合作?
Sharpa的运营与商业计划是什么?
Sharpa为什么会引发关注?
触觉是不是灵巧操作的关键?
CraftNet的创新之处?
为什么英伟达会和Sharpa合作?
Sharpa的运营与商业计划是什么?
本文为「甲子光年」对话Sharpa核心团队实录,经「甲子光年」整理编辑,在不改变原意的基础上有所删改。
1.要做就做与人类1:1同构灵巧手
甲子光年:之前很多人以为你们是一家做灵巧手的公司,所以你们对自己定位是什么?
Alicia:可能是Sharpa的灵巧手做得太好了(笑),导致很多人以为我们就是个做灵巧手的公司。
而我们的秘密武器就是触觉以及触觉AI,我们的核心定位是一家以触觉AI为驱动的全栈灵巧机器人公司。
从去年5月份我们在ICRA(国际机器人与自动化会议)第一次亮相时,我们带去的就是一整台完整的机器人。但当时所有人的注意力全被那只手吸引了。

Alicia Veneziani,图片来源:Sharpa
甲子光年:的确,不论是去年的ICRA,还是今年的CES和GTC,你们展位的人都不少。
Alicia:实际上,我们从一开始就没打算只做手,我们一直在做机器人整机。
我们内部有个比喻:我们造的这只灵巧手,其实更像是汽车的发动机。我们要把各种不同的系统集成到这辆“车”里,所以我们本质上是“造车”的(做全栈机器人系统),只不过我们的手做得特别好,这只手就成了我们这辆车的核心发动机。

Sharpa GTC展位,图片来源:Sharpa
甲子光年:这个比喻很有意思,我也发现,其实你们一直在强调机器人的“灵巧操作”以及“全身控制”,而不光是“手”。
张凯峰:这其实是我们的愿景。我们常说“We manufacture time by making robots useful”(我们通过让机器人变得有用,来为人类创造时间)。我们想做真正能干活、有用的机器人,去承担那些人们不愿意干的脏活累活,从而把人类的时间真正解放出来。
甲子光年:我注意到,Sharpa灵巧机械手Wave是和人类1:1同构的,所以做到1:1同构很难吗?
张凯峰:灵巧手做到1:1同构非常难。比如要做到成年男性的手部大小,还要具备人手大部分的自由度。我们的灵巧手有很多特性,比如指尖力矩能达到两公斤,运动频率是四赫兹,你需要兼具速度和力量。其次,要在这么小的空间里集成强有力的电机,同时做好整个系统的集成,工程难度极大。
Alicia:我认为这取决于我们如何定义“相似”。如果我们要求外观和功能都相似,希望机械手能像人手一样拥有同等的自由度、完成同等范围的精细动作,就需要把大量内部零件塞进一个极小的表面积里。这意味着必须使用超微型的驱动器,在极其有限的空间内实现同等功能,这就是保持1:1比例的难点所在。
甲子光年:但是业内也有声音说,灵巧手硬件本身似乎并不那么重要。
Alicia:现在有个误区,有人觉得有了AI算法控制,硬件问题就不存在了。这完全是错的,硬件的痛点依然在那儿。所以我们坚持深耕硬件工程,才能自己设计组件并快速迭代。大部分公司的手只能往大了做,但做大了就用不了人类的工具,比如普通的剪刀。
甲子光年:之前我们也看过各种灵巧手产品。有的公司会强调手的抓握力和负载能力,你们似乎没有强调这方面能力。
Alicia:如果他们的目标是工业里的分拣(pick and place)或搬运,那负载能力当然重要。但搬运东西真的需要人形机器人、需要灵巧手吗?
我们的核心聚焦点是灵巧操作(dexterous tasks)。这其中可能也会涉及搬运,但那绝不是我们最核心的应用场景。所以除了负载能力,我们必须考量更多其他维度的指标。
甲子光年:为什么说22个自由度是一个非常关键的设计?为什么偏偏是22个?
Alicia:其实这跟“为什么要做成1:1类人手”逻辑有点类似。人手大概有27个自由度,但在机器人上,22个自由度已经完全足够用了。这是我们在成本、工程实现难度和实际功能之间找到的一个最佳平衡点。

Sharpa灵巧机械手Wave,图片来源:Sharpa
甲子光年:已经有其他头部机器人公司使用了Wave,甚至它还上了春晚。你们有什么优势能让客户买单?
张凯峰:我想最主要的原因有两点。
第一,一致性,这包括我们不同批次的硬件之间高度一致,同时我们的Sim-to-Real Gap足够小。我们自己做过很多Sim-to-Real的算法和模型,在这个过程中不断迭代并更好地标定了我们的硬件,从而把这个Gap降到了最小。
第二,可靠性。我们的手确实能经受住高强度、长时间的使用,并且性能非常稳定。
Alicia:其实这并不是公开标价(list price),我们目前只为客户提供定制报价(custom price)。
甲子光年:你们团队是如何平衡产品性能和成本的?价格可能再降低一些吗?
Alicia:在设计时,我们第一优先级的考量绝对是性能(performance)。我们必须确保这只手在各类场景中能真正干活。其次是极高的可靠性(reliability),因为我们着眼于长期的服务场景,它必须能扛得住长时间的持续使用。第三个考量才是成本。因为如果达不到及格的性能,成本再低也没意义。
我们的核心聚焦点是灵巧操作,而不在搬重物。如果只是搬运,用个便宜的夹爪就够了,客户完全没必要花高价买一只复杂的灵巧手。
解决技术问题后我们肯定会盯紧价格。只要我们不是用“黄金”来造手,凭借团队扎实的硬件工程能力,我们有信心把价格降到大规模量产所需的水平。
大家看BOM(物料清单)就知道硬件底座的成本逻辑,一旦行业进入大规模量产,比如未来出货量达到100万台时,规模效应自然会把成本打下来,所以我们对控制成本非常有信心。
2.没有触觉,是一种新形式的失明
甲子光年:今天机器人已经可以跑、跳、走,但在精细操作上仍然不如人类。从技术角度看,机器人灵巧操作的核心瓶颈是什么?
张凯峰:核心瓶颈就是数据。
灵巧操作有三类数据来源。第一类是遥操作数据。它最大的痛点是“操作员感受不到机器人的感受”,遥操作员操作起来非常不直观(not intuitive),所以很难用这种方式去采集像手中把玩(in-hand manipulation)这类极度精细的操作数据。
第二类是以人为中心的数据采集方式。比如斯坦福大学团队(Stanford)队做的同构外骨骼手套DexUMI,以及麻省理工学院(MIT)和加州大学伯克利分校(UC Berkeley)联合推出的无源手部外骨骼系统DexOP。DexUMI会带来视觉上的Gap,因为腕部相机看到的是人戴着数据手套,而不是机械手;而DexOP则相反,它看到的是灵巧手本身,所以视觉Gap小,但是对于高自由度的灵巧手来说,它的状态Gap会比较大。
第三类就是动捕(MOCAP)数据。其实又回到了刚才说的functional retargeting的挑战。这个问题真的非常难,尤其是实时的重定向。我们不仅希望在空间上把人手关键点1:1映射过去(kinematics-based),更希望“操作语义”是一致的,这是非常困难的。
甲子光年:还有其他难点吗?比如模型和评测维度?
张凯峰:模型维度的话,最大的挑战在于鲁棒性(robustness)和泛化能力(generalization)。你能不能做到物体级别、环境级别甚至任务级别的泛化?能不能拿出一个真正具有99.999%鲁棒性的通用策略?目前还做不到。
评测方面也是限制我们算法迭代效率的瓶颈。一个是可靠性问题。今天测10次,成功率80%和70%其实说明不了太大问题,可能只是A策略比B策略碰巧多成功了一次。另一个是人力成本极高。
评测则需要大量人力去控制环境变量、重置场景、统计数据,极其消耗精力。这些都是目前限制灵巧操作发展的核心瓶颈。
甲子光年:触觉是不是灵巧操作的关键?
张凯峰:我认为极其重要。
因为在操作过程中,无论是数据采集还是模型推理,都会遇到严重的“自遮挡”或者被物体“遮挡”的问题。此外,触觉能赋予机器人“手感”。人类在做微操时是有精细手感的,但目前的机器人还做不到这点。
甲子光年:Alicia,我记得你们曾经提到“Tactileless is the new blindness(没有触觉,是一种新形式的失明)”。
Alicia:是的,我们坚信,如果没有触觉,有些任务机器人根本无法完成。特别是那些步骤繁琐的Long-horizon(长视距/长程)任务,想完全依靠视觉让机器人自主完成,如果不是不可能,也是极其困难的。
我们想想人类的操作就明白了:如果你想擦一个花瓶,你的手会绕到花瓶背面去擦,这时你的眼睛是看不到手的对吧?但你依然能擦干净,而且不会把花瓶打碎,因为你能“摸”到它。在这种情况下,视觉是被遮挡(occluded)的。
再比如把数据线插进USB接口、或者把零件卡进去的时候,因为空间太狭小,摄像头不可能无死角覆盖,你根本看不到线头插进去的瞬间。这时候,触觉就成了唯一的解法。
同时凯峰和清华大学合作的《Spatially-anchored Tactile Awareness for Robust Dexterous Manipulation》论文,更是证明了有了触觉,一些原本机器人根本不可能自主完成的任务,比如插USB线、安装灯泡、发扑克牌等变得可能了。

《Spatially-anchored Tactile Awareness for Robust Dexterous Manipulation》论文,图片来源:受访者
有大量顶级学术研究证实了触觉在加速机器人训练中的作用。这就是我们如此看好触觉AI的原因:它不仅是我们的信仰,更得到了科学界的验证。
甲子光年:我突然觉得这挺像自动驾驶领域的情况:行业里既有特斯拉那种纯视觉路线,也有“摄像头+激光雷达”的融合方案。你们提到了机器人触觉,其实很像激光雷达在自动驾驶中的角色。一旦机器人的视觉受阻或存在盲区,触觉就能作为全新的数据源来补足视觉短板。
Alicia:确实很像,但我认为触觉在机器人身上的重要性,超过了激光雷达在车上的重要性。
车的逻辑是“避障”,它所有的目标是“不要碰到任何东西”,碰到就是事故。而机器人的逻辑相反,它无时无刻不在跟这个世界“接触”,尤其是手部。
对于那些看不见或处于视觉盲区的地方,触觉尤其不可或缺。
甲子光年:做好触觉,有哪些挑战?
Alicia:这件事在技术上极其复杂,主要有三个核心维度的挑战。Sharpa研究副总裁朱雪洲在GTC的演讲就详细提到了几个核心原因:一方面是凯峰说的映射问题,你必须得有这样一只带触觉的灵巧手,才能实现底层的物理分层;另一方面是模态竞争问题,比如视觉和触觉之间会有模态竞争;最后还有一个关键点,就是计算成本的开销问题。
3.从粗略动作到精准动作
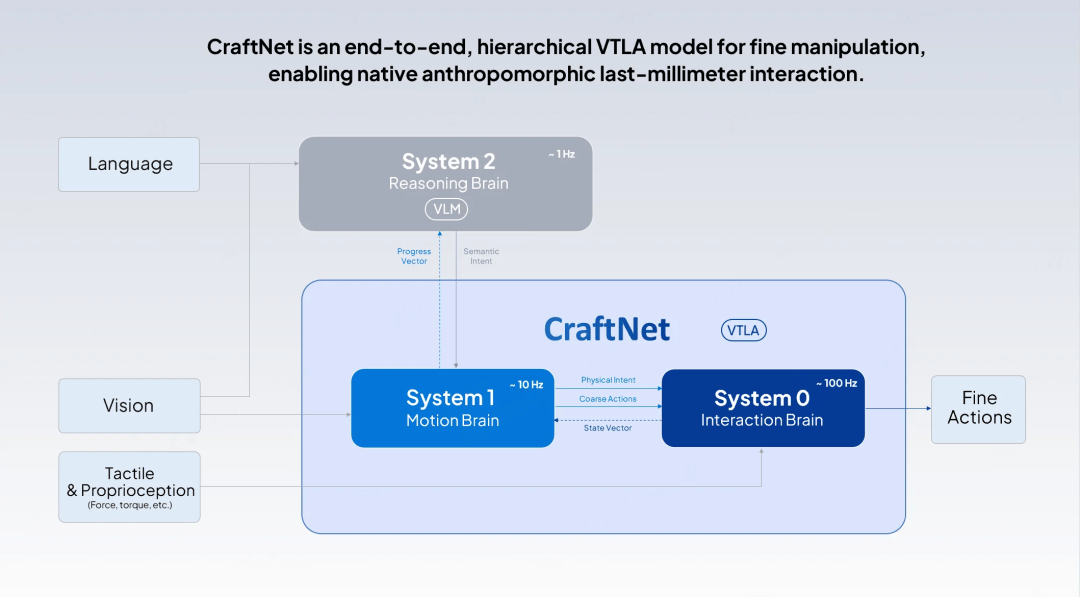
甲子光年:具身智能的研究大致分为两个核心方向:Locomotion(移动能力)与Manipulation(操作能力)。Sharpa提出的CraftNet是一种VTLA(Vision Tactile Language Action,视觉-触觉-语言-动作)模型,我的理解是,你们在Locomotion与Manipulation之外增加了第三个维度:Perception(感知),对吗?
张凯峰:我常常开玩笑说,Locomotion其实也是一种特殊的Manipulation——是人用两只脚在“操控”地球。如果今天我们已经彻底解决了操作问题,回过头看,一定能用同一套框架既解决移动、又解决操作。
这两者最大的不同在于:Locomotion是将“自身状态”调整到目标状态,而Manipulation是将“被操作的物体”调整到目标状态。这就要求你必须实时获取被操作物体的姿态信息,也就是Perception。
2000年以前做机器人的人,常常假设Vision Perception(视觉感知)问题已经解决了,所以直接在action(动作)层面寻求突破点。但今天我们发现这远远不够,必须把感知和动作放到一个闭环里去做。
甲子光年:CraftNet的分层设计很像人类的神经系统。System 2负责想,是推理大脑(the Reasoning Brain);System 1负责动,是运动大脑(the Motion Brain) ;System 0负责做,是交互大脑 (the Interaction Brain) 。但是这三个系统频率不一样,如何避免系统之间的“打架”?
成为付费用户可以阅读 Sharpa 所有资料
了解更多 →